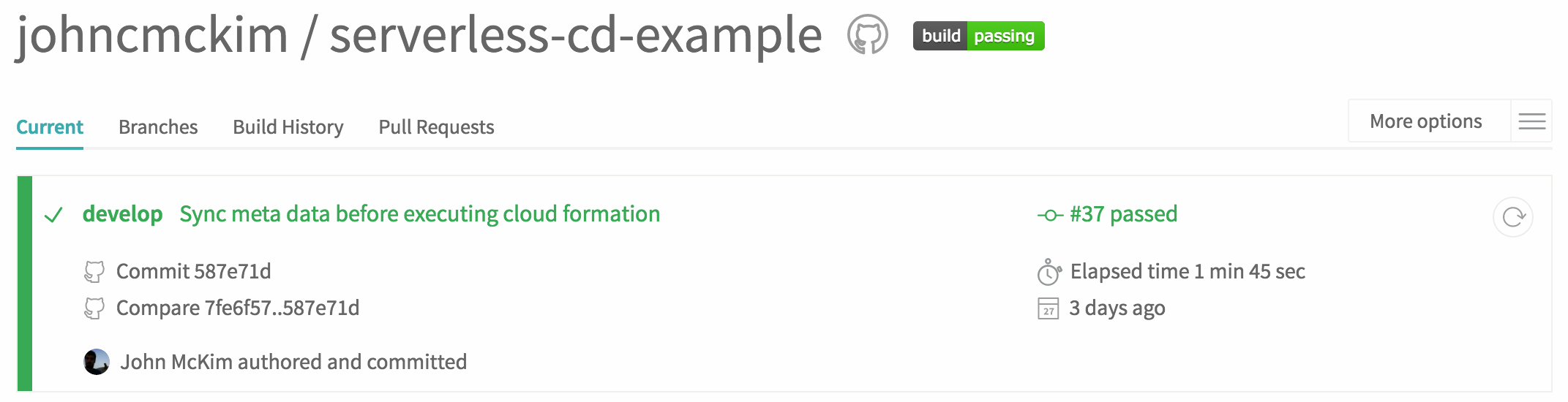
Continuous Deployments with Serverless v0.5
UPDATE: Serverless 1.0 was released earlier this year. There are a lot of improvements in v1.x. I suggest you go and read the docs for the most up to date information.
Over the last month I have been exploring and learning about the Serverless Framework. After learning about the framework itself, I decided to explore Continuous Deployments with Serverless. The two aspects I wanted to explore were how environments are isolated in AWS and how to automate the deployment.
In this example, I am going to leverage Git and Gitflow to deploy code to production and dev. The *master *branch will be deployed to the **production **environment on tagged commits. Deploying on a tag adds a ‘human’ step to the deployment process. The *develop *branch will be deployed to the **dev **environment continuously. This allows developers to see their changes integrated into the dev environment as soon as possible. This is a simplified version of Gitflow is good for small projects.
The Serverless Framework separates environments through stages. A stage allows you to separate and isolate a project’s AWS resources. Lambda and API Gateway have stages built in to the service while other AWS resource do not.
*Lambda **Lambda supports stages through *versions and aliases. Rather than simply updating an functions, when a function is deployed to Lambda, a new version of the function is created. An alias is a marker that points to a particular version of your Lambda function. Importantly, each version and alias has a Amazon Resource Name (ARN). I suggest reading the Lambda docs for further details.
The Serverless Framework leverages Lambda versions and aliases to isolate stages. When a function is deployed, a new version is created and the function is aliased using the name of the current stage.
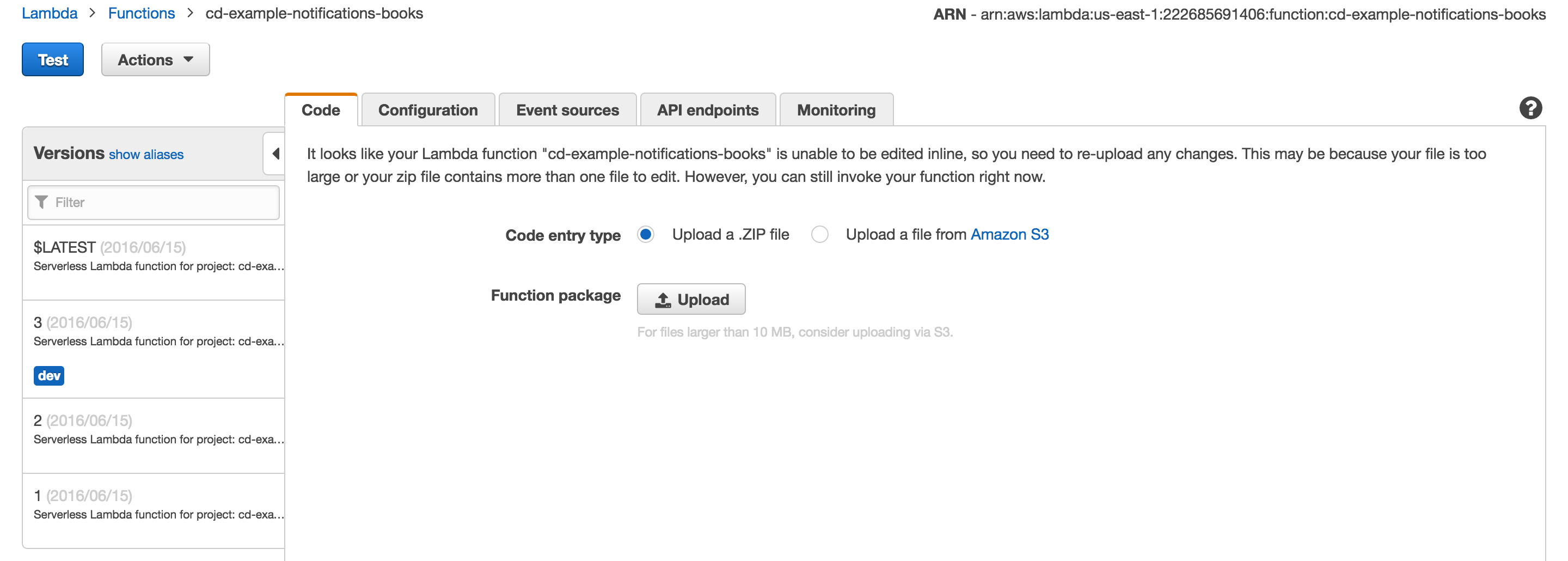 See dev alias and versions in the left panel
See dev alias and versions in the left panel
The endpoints and events that you configure for your functions, point to a Lambda function alias that corresponds to the stage name. This allows you to deploy functions to a stage without affecting other stages.
*API Gateway **API Gateway has *stages built into the service. Each stage can have different endpoints, settings and variables. The Serverless Framework uses a stage variable, functionAlias, to point an API Gateway endpoint to the correct Lambda function.
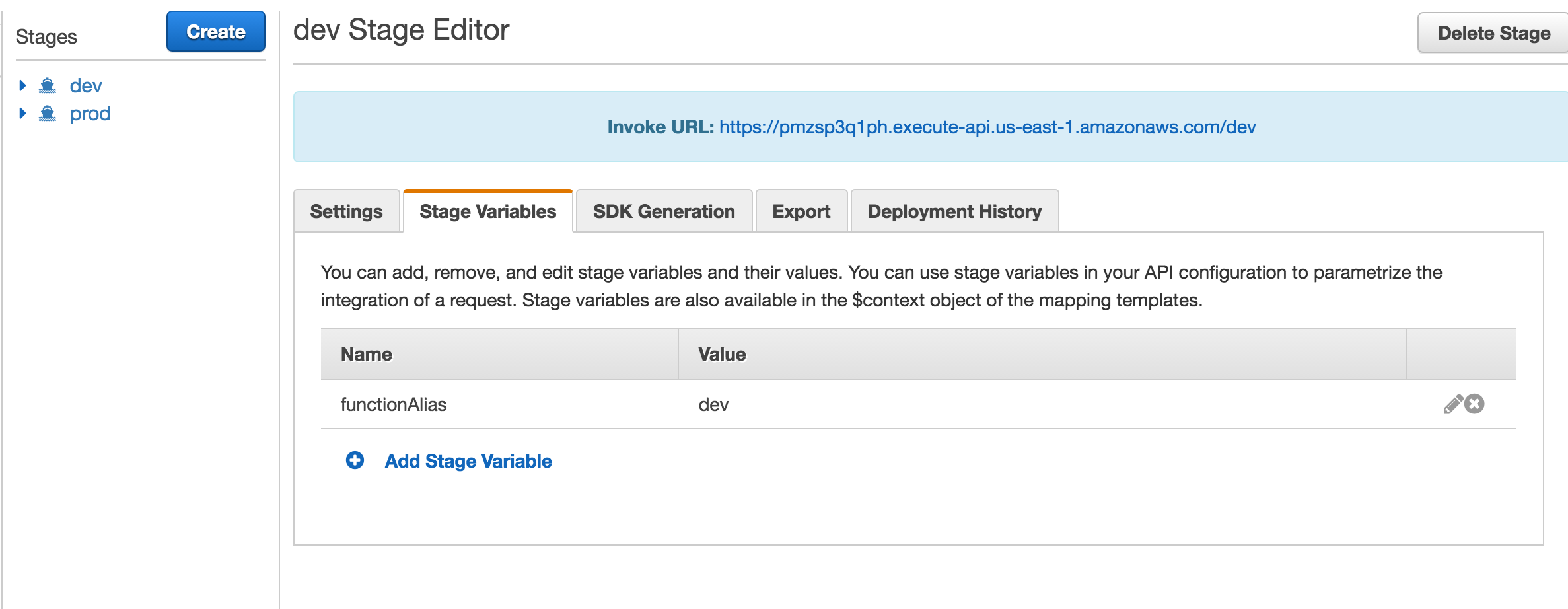 Stage variable for dev
Stage variable for dev
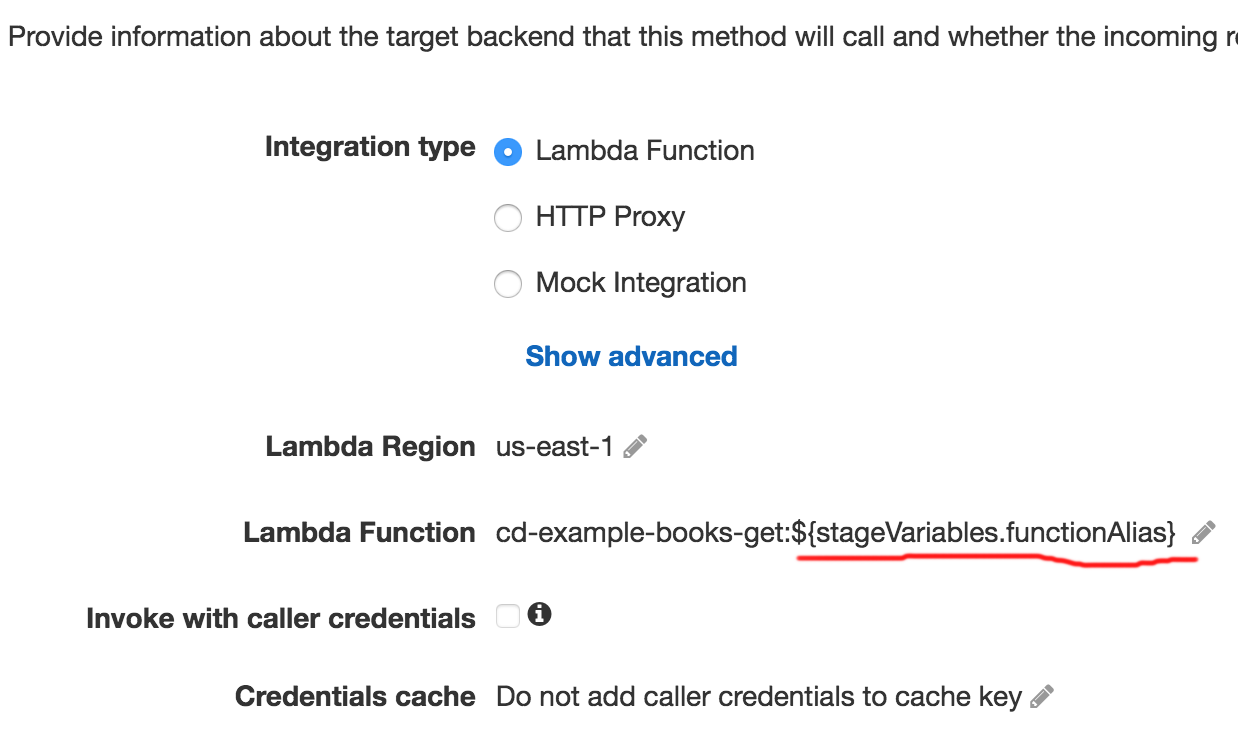 Endpoint configuration
Endpoint configuration
Other Resources All other resources in the Serverless Framework are deployed using CloudFormation. Each stage has a separate CloudFormation stack. This allows you to isolate each stage’s resources.
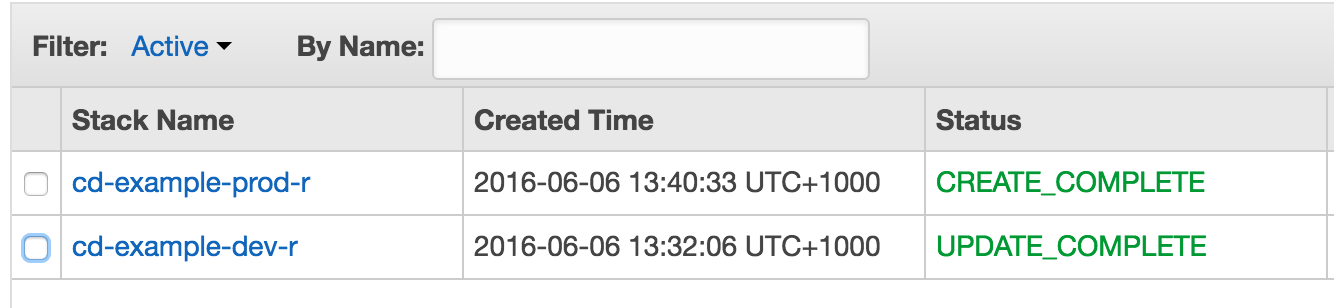 CloudFormation stacks for each stage
CloudFormation stacks for each stage
Deploying a Serverless v0.5 project has four basic steps:
Update the resources via CloudFormation
Deploy all Lambda functions
Connect Lambda functions to events
Deploy API Gateway endpoints
While running these commands from your computer is simple enough, automating these steps is a little bit tricker. Every Serverless project has a _meta folder that contains the project’s metadata. The project metadata stores the CloudFormation outputs as variables per region and stage. Since this information is sensitive, it is gitignored by default. As a result, when your build server clones the project, it is missing the variables it requires to deploy your project.
Managing Metadata There are multiple approaches to managing Serverless metadata. My approach is to maintain a ‘source of truth’. I use the Serverless Meta Sync plugin to store project metadata in Amazon S3. An alternative is to commit the _meta folder and protect it using Serverless Secrets. For the purposes of this exercise I will use the meta sync approach.
Preparing a freshly cloned Serverless deployment using meta sync involves two steps. The first step is to initialise the project.
sls project init -c -r $REGION -s $STAGE
This creates the _meta folder with region and stage specific metadata. The -c argument stops Serverless deploying the CloudFormation resources. This is important as at this stage, the project does not have the required metadata to deploy the project.
The next step is to sync the metadata using the Serverless Meta sync plugin. This command retrieves the region and stage specific metadata stored in Amazon S3. Once this step is complete, the project has the metadata required to deploy the project.
sls meta sync -r $REGION -s $STAGE
If you are considering this approach, be aware that your millage may vary. This approach depends on metadata being synced every time resources a deployed. If your team does any manual deployments, they must ensure they sync the metadata. Discussions on the Serverless Github project and Gitter channel show that this approach works for some, while others prefer to use Serverless Secrets.
The Serverless team is working hard to improve this area for version 1 of the framework. I am looking forward to seeing what they can produce.
Deploying the Project Once the Metadata is prepared, we can deploy the project. The four commands we need to execute are:
sls resources deploy -r $REGION -s $STAGE
sls function deploy -a -r $REGION -s $STAGE
sls event deploy -a -r $REGION -s $STAGE
sls endpoint deploy -a -r $REGION -s $STAGE
To automated these commands, we need to execute each command and check the result before moving on to the next command. If there is a failure, we need to exit and fail the build.
If you are considering this approach, be aware that this does not rollback on failure. It is entirely possible that the resources deploy may pass and one of the subsequent steps will fail. This could leave your environment in a bad state.
According to this issue, Version 1 of the Serverless Framework will deploy all your resources using CloudFormation. CloudFormation is designed to rollback changes after a failed step. If all four steps are integrated into CloudFormation, this should prevent the application from ending up in a bad state on a failure.
**Putting it Together **To deploy my test project I created a shell script to execute on Travis CI. The deploy script selects a stage based on the branch name, syncs the metadata and deploys the project.
To test these processes I have created a basic serverless project on GitHub. I am using Travis CI to run tests and deploy the project. I started the project with a single function called *books/get *with a single endpoint.
module.exports.handler = function(event, context, cb) {
return cb(null, {
message: ‘success’
});
};
I pushed the project to GitHub and Travis started a building the project. After a few revisions, I was able to get Travis to deploy the function and the endpoint.
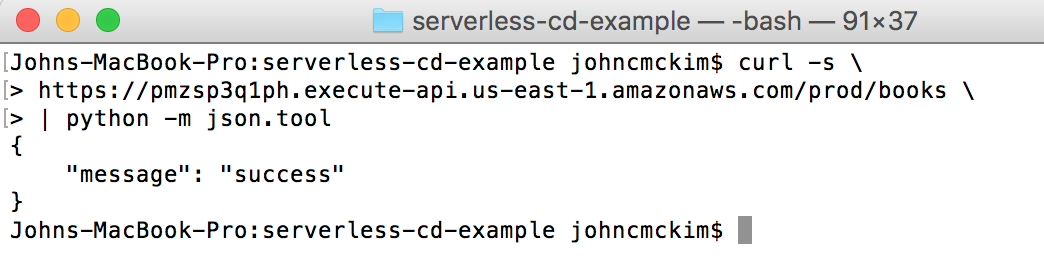 Prod endpoint
Prod endpoint
To test the CD process I created a new branch, develop, and updated the books/get function.
module.exports.handler = function(event, context, cb) {
return cb(null, {
stage: process.env.SERVERLESS_STAGE,
app_version: 1,
message: ‘success’
});
};
After pushing the change, Travis started a new build and deployed the updated endpoint to the dev stage.
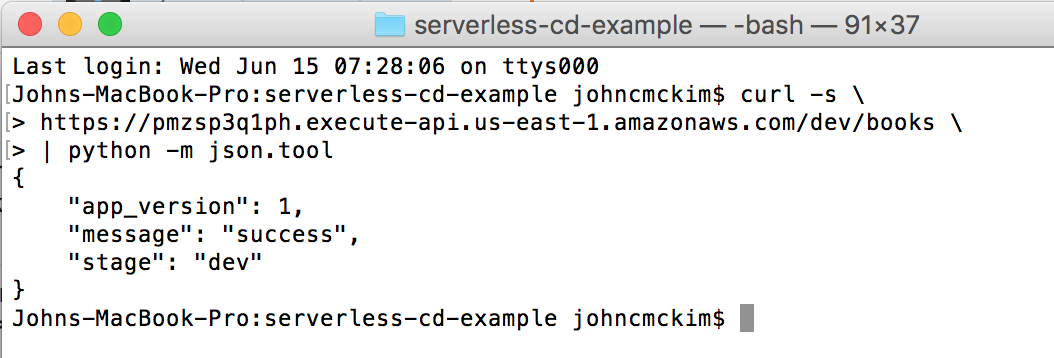 Dev endpoint
Dev endpoint
I then added new functions and endpoints to the project and pushed the changes to the develop branch.
 New endpoints on the Dev stage
New endpoints on the Dev stage
The full code for my test project is up on GitHub. You can also check out the build logs on Travis CI.
While this process is working there are still areas for improvement. I would like to add unit tests, linting and validate the CloudFormation template before the project is deployed. I would also like to automatically release the API Gateway clients after a successful deployment. There are improvements to be made with Metadata management and rolling back on failure. However, as these should be improved in V1 of the Serverless Framework, I will be waiting for those changes rather than trying to solve the issue myself.
One area I have not touched on is the IAM Policy for the IAM user that used to deploy the project. If you are interested in this, reach out to me and I can provide the policy I have used.
Thanks for reading, I hope you found it useful. If you have any thoughts or suggestions about how to please add comment or create an issue on Github.
If you want to see more articles like this, follow me on Medium or Twitter.